Databricks Asset Bundles: Stabiele configuratie van jouw workspaces

Tag(s)
Binnen het data landschap zien we bij onze klanten vaak dezelfde uitdagingen terugkomen. Het ontsluiten van enkele databronnen is één ding; dit schaalbaar en gestandaardiseerd doen is een heel ander verhaal. Hoe zorg je ervoor dat je datastromen en de benodigde infrastructuur stabiel in productie krijgt? En hoe gaat dit in zijn werk wanneer er meerdere developers – laat staan developer teams – tegelijk bezig zijn dit voor elkaar te krijgen?
Een belangrijk deel van het antwoord ligt bij Databricks; de go-to voor organisaties waar meerdere developers – of zelfs meerdere developer teams – verantwoordelijk zijn voor het ontsluiten van data en het creëren van data producten.
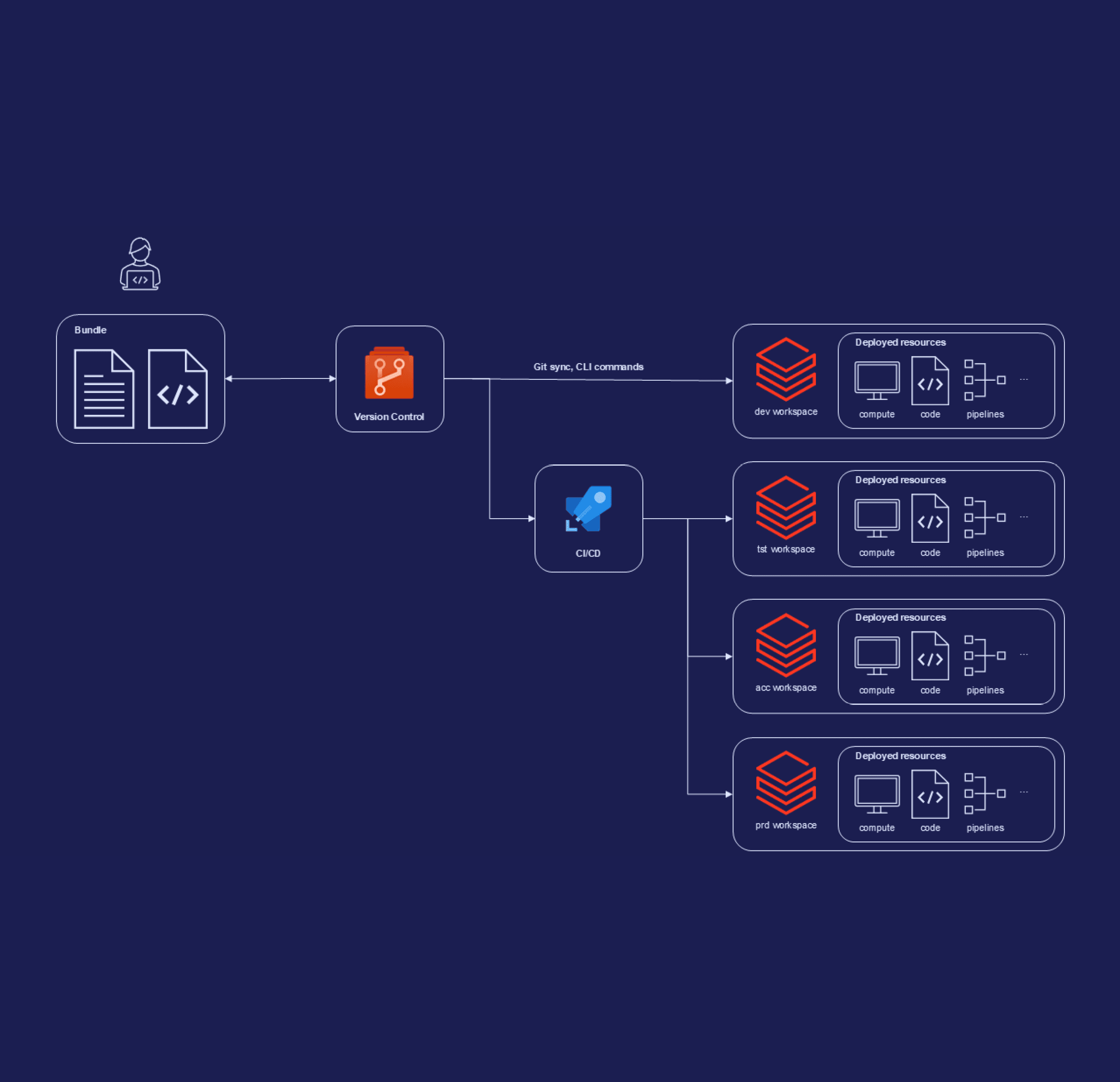
Daarbij zijn Databricks Asset Bundles (DABs) je beste vriend: een tool om data pipelines en bijbehorende resources as-code te configureren – vergelijkbaar met Infrastructure-as-Code, maar dan voor je data. Deze bundles kunnen vervolgens eenvoudig geïntegreerd worden met CI pipelines, om van omgeving naar omgeving te kunnen deployen. Met DABs leg je de basis voor gestandaardiseerde, herhaalbare en schaalbare deployments van je Databricks-omgevingen – en precies dát maakt het verschil tussen proof-of-concept en productie.