Databricks Asset Bundles: Stable configuration of your workspaces

Tag(s)
Within the data landscape, we often see the same challenges recurring among our clients. Unlocking single data sources is one thing; doing so in a scalable and standardised way is quite another. How do you make sure you get data streams and the required infrastructure into production in a stable way? And how does this work when multiple developers – let alone developer teams – are working on getting this done at the same time?
An important part of the answer lies with Databricks; the go-to for organisations where multiple developers – or even multiple developer teams – are responsible for unlocking data and creating data products.
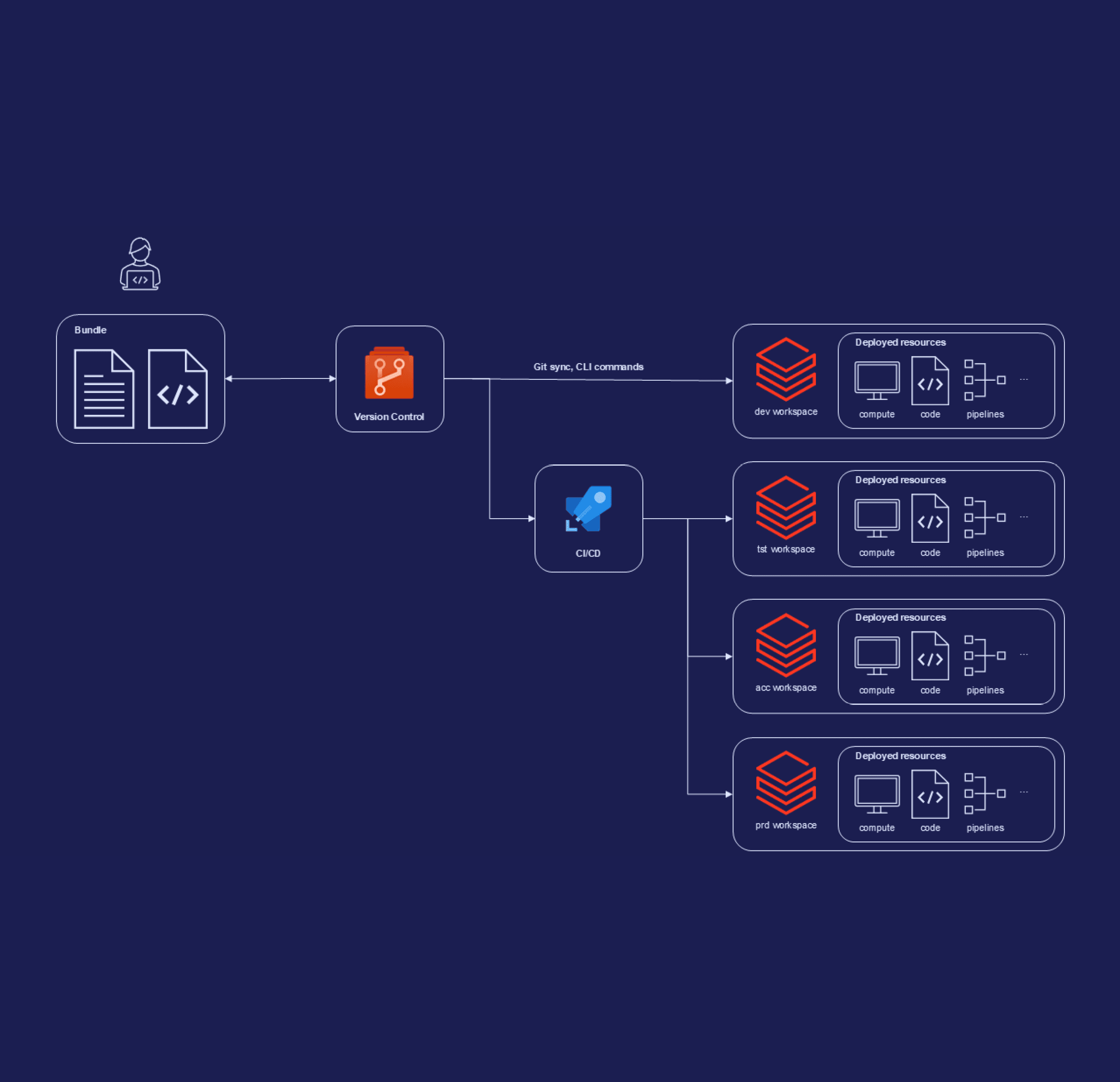
In doing so, Databricks Asset Bundles (DABs) are your best friend: a tool to configure data pipelines and associated resources as-code – similar to Infrastructure-as-Code, but for your data. These bundles can then be easily integrated with CI pipelines to deploy from environment to environment. With DABs, you lay the foundations for standardised, repeatable and scalable deployments of your Databricks environments – and exactly that makes the difference between proof-of-concept and production.